dbt
There are 2 sources that provide integration with dbt
| Source Module | Documentation |
| The artifacts used by this source are:
|
| This source pulls dbt metadata directly from the dbt Cloud APIs. You'll need to have a dbt Cloud job set up to run your dbt project, and "Generate docs on run" should be enabled. The token should have the "read metadata" permission. To get the required IDs, go to the job details page (this is the one with the "Run History" table), and look at the URL. It should look something like this: https://cloud.getdbt.com/next/deploy/107298/projects/175705/jobs/148094. In this example, the account ID is 107298, the project ID is 175705, and the job ID is 148094. Read more... |
Ingesting metadata from dbt requires either using the dbt module or the dbt-cloud module.
Concept Mapping
| Source Concept | DataHub Concept | Notes |
|---|---|---|
"dbt" | Data Platform | |
| dbt Source | Dataset | Subtype source |
| dbt Seed | Dataset | Subtype seed |
| dbt Model | Dataset | Subtype model |
| dbt Snapshot | Dataset | Subtype snapshot |
| dbt Test | Assertion | |
| dbt Test Result | Assertion Run Result |
Note:
- It also generates lineage between the
dbtnodes (e.g. ephemeral nodes that depend on other dbt sources) as well as lineage between thedbtnodes and the underlying (target) platform nodes (e.g. BigQuery Table -> dbt Source, dbt View -> BigQuery View). - We also support automated actions (like add a tag, term or owner) based on properties defined in dbt meta.
Module dbt
Important Capabilities
| Capability | Status | Notes |
|---|---|---|
| Dataset Usage | ❌ | |
| Detect Deleted Entities | ✅ | Enabled via stateful ingestion |
| Table-Level Lineage | ✅ | Enabled by default |
The artifacts used by this source are:
- dbt manifest file
- This file contains model, source, tests and lineage data.
- dbt catalog file
- This file contains schema data.
- dbt does not record schema data for Ephemeral models, as such datahub will show Ephemeral models in the lineage, however there will be no associated schema for Ephemeral models
- dbt sources file
- This file contains metadata for sources with freshness checks.
- We transfer dbt's freshness checks to DataHub's last-modified fields.
- Note that this file is optional – if not specified, we'll use time of ingestion instead as a proxy for time last-modified.
- dbt run_results file
- This file contains metadata from the result of a dbt run, e.g. dbt test
- When provided, we transfer dbt test run results into assertion run events to see a timeline of test runs on the dataset
CLI based Ingestion
Install the Plugin
pip install 'acryl-datahub[dbt]'
Starter Recipe
Check out the following recipe to get started with ingestion! See below for full configuration options.
For general pointers on writing and running a recipe, see our main recipe guide.
source:
type: "dbt"
config:
# Coordinates
# To use this as-is, set the environment variable DBT_PROJECT_ROOT to the root folder of your dbt project
manifest_path: "${DBT_PROJECT_ROOT}/target/manifest_file.json"
catalog_path: "${DBT_PROJECT_ROOT}/target/catalog_file.json"
sources_path: "${DBT_PROJECT_ROOT}/target/sources_file.json" # optional for freshness
test_results_path: "${DBT_PROJECT_ROOT}/target/run_results.json" # optional for recording dbt test results after running dbt test
# Options
target_platform: "my_target_platform_id" # e.g. bigquery/postgres/etc.
# sink configs
Config Details
- Options
- Schema
Note that a . is used to denote nested fields in the YAML recipe.
| Field | Description |
|---|---|
catalog_path ✅ string | Path to dbt catalog JSON. See https://docs.getdbt.com/reference/artifacts/catalog-json Note this can be a local file or a URI. |
manifest_path ✅ string | Path to dbt manifest JSON. See https://docs.getdbt.com/reference/artifacts/manifest-json Note this can be a local file or a URI. |
target_platform ✅ string | The platform that dbt is loading onto. (e.g. bigquery / redshift / postgres etc.) |
column_meta_mapping object | mapping rules that will be executed against dbt column meta properties. Refer to the section below on dbt meta automated mappings. Default: {} |
convert_column_urns_to_lowercase boolean | When enabled, converts column URNs to lowercase to ensure cross-platform compatibility. If target_platform is Snowflake, the default is True. Default: False |
enable_meta_mapping boolean | When enabled, applies the mappings that are defined through the meta_mapping directives. Default: True |
enable_owner_extraction boolean | When enabled, ownership info will be extracted from the dbt meta Default: True |
enable_query_tag_mapping boolean | When enabled, applies the mappings that are defined through the query_tag_mapping directives. Default: True |
include_env_in_assertion_guid boolean | Prior to version 0.9.4.2, the assertion GUIDs did not include the environment. If you're using multiple dbt ingestion that are only distinguished by env, then you should set this flag to True. Default: False |
incremental_lineage boolean | When enabled, emits lineage as incremental to existing lineage already in DataHub. When disabled, re-states lineage on each run. Default: True |
meta_mapping object | mapping rules that will be executed against dbt meta properties. Refer to the section below on dbt meta automated mappings. Default: {} |
owner_extraction_pattern string | Regex string to extract owner from the dbt node using the (?P<name>...) syntax of the match object, where the group name must be owner. Examples: (1)r"(?P<owner>(.*)): (\w+) (\w+)" will extract jdoe as the owner from "jdoe: John Doe" (2) r"@(?P<owner>(.*))" will extract alice as the owner from "@alice". |
platform_instance string | The instance of the platform that all assets produced by this recipe belong to |
query_tag_mapping object | mapping rules that will be executed against dbt query_tag meta properties. Refer to the section below on dbt meta automated mappings. Default: {} |
sources_path string | Path to dbt sources JSON. See https://docs.getdbt.com/reference/artifacts/sources-json. If not specified, last-modified fields will not be populated. Note this can be a local file or a URI. |
sql_parser_use_external_process boolean | When enabled, sql parser will run in isolated in a separate process. This can affect processing time but can protect from sql parser's mem leak. Default: False |
strip_user_ids_from_email boolean | Whether or not to strip email id while adding owners using dbt meta actions. Default: False |
tag_prefix string | Prefix added to tags during ingestion. Default: dbt: |
target_platform_instance string | The platform instance for the platform that dbt is operating on. Use this if you have multiple instances of the same platform (e.g. redshift) and need to distinguish between them. |
test_results_path string | Path to output of dbt test run as run_results file in JSON format. See https://docs.getdbt.com/reference/artifacts/run-results-json. If not specified, test execution results will not be populated in DataHub. |
test_warnings_are_errors boolean | When enabled, dbt test warnings will be treated as failures. Default: False |
use_compiled_code boolean | When enabled, uses the compiled dbt code instead of the raw dbt node definition. Default: False |
use_identifiers boolean | Use model identifier instead of model name if defined (if not, default to model name). Default: False |
write_semantics string | Whether the new tags, terms and owners to be added will override the existing ones added only by this source or not. Value for this config can be "PATCH" or "OVERRIDE" Default: PATCH |
env string | Environment to use in namespace when constructing URNs. Default: PROD |
aws_connection AwsConnectionConfig | When fetching manifest files from s3, configuration for aws connection details |
aws_connection.aws_region ❓ string | AWS region code. |
aws_connection.aws_access_key_id string | AWS access key ID. Can be auto-detected, see the AWS boto3 docs for details. |
aws_connection.aws_endpoint_url string | The AWS service endpoint. This is normally constructed automatically, but can be overridden here. |
aws_connection.aws_profile string | Named AWS profile to use. Only used if access key / secret are unset. If not set the default will be used |
aws_connection.aws_proxy map(str,string) | |
aws_connection.aws_secret_access_key string | AWS secret access key. Can be auto-detected, see the AWS boto3 docs for details. |
aws_connection.aws_session_token string | AWS session token. Can be auto-detected, see the AWS boto3 docs for details. |
aws_connection.aws_role One of string, union(anyOf), string, AwsAssumeRoleConfig | AWS roles to assume. If using the string format, the role ARN can be specified directly. If using the object format, the role can be specified in the RoleArn field and additional available arguments are documented at https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sts.html?highlight=assume_role#STS.Client.assume_role |
aws_connection.aws_role.RoleArn ❓ string | ARN of the role to assume. |
aws_connection.aws_role.ExternalId string | External ID to use when assuming the role. |
entities_enabled DBTEntitiesEnabled | Controls for enabling / disabling metadata emission for different dbt entities (models, test definitions, test results, etc.) Default: {'models': 'YES', 'sources': 'YES', 'seeds': 'YES'... |
entities_enabled.models Enum | Emit metadata for dbt models when set to Yes or Only Default: YES |
entities_enabled.seeds Enum | Emit metadata for dbt seeds when set to Yes or Only Default: YES |
entities_enabled.snapshots Enum | Emit metadata for dbt snapshots when set to Yes or Only Default: YES |
entities_enabled.sources Enum | Emit metadata for dbt sources when set to Yes or Only Default: YES |
entities_enabled.test_definitions Enum | Emit metadata for test definitions when enabled when set to Yes or Only Default: YES |
entities_enabled.test_results Enum | Emit metadata for test results when set to Yes or Only Default: YES |
git_info GitReference | Reference to your git location to enable easy navigation from DataHub to your dbt files. |
git_info.repo ❓ string | Name of your Git repo e.g. https://github.com/datahub-project/datahub or https://gitlab.com/gitlab-org/gitlab. If organization/repo is provided, we assume it is a GitHub repo. |
git_info.branch string | Branch on which your files live by default. Typically main or master. This can also be a commit hash. Default: main |
git_info.url_template string | Template for generating a URL to a file in the repo e.g. '{repo_url}/blob/{branch}/{file_path}'. We can infer this for GitHub and GitLab repos, and it is otherwise required.It supports the following variables: {repo_url}, {branch}, {file_path} |
node_name_pattern AllowDenyPattern | regex patterns for dbt model names to filter in ingestion. Default: {'allow': ['.*'], 'deny': [], 'ignoreCase': True} |
node_name_pattern.allow array(string) | |
node_name_pattern.deny array(string) | |
node_name_pattern.ignoreCase boolean | Whether to ignore case sensitivity during pattern matching. Default: True |
stateful_ingestion StatefulStaleMetadataRemovalConfig | DBT Stateful Ingestion Config. |
stateful_ingestion.enabled boolean | The type of the ingestion state provider registered with datahub. Default: False |
stateful_ingestion.remove_stale_metadata boolean | Soft-deletes the entities present in the last successful run but missing in the current run with stateful_ingestion enabled. Default: True |
The JSONSchema for this configuration is inlined below.
{
"title": "DBTCoreConfig",
"description": "Base configuration class for stateful ingestion for source configs to inherit from.",
"type": "object",
"properties": {
"incremental_lineage": {
"title": "Incremental Lineage",
"description": "When enabled, emits lineage as incremental to existing lineage already in DataHub. When disabled, re-states lineage on each run.",
"default": true,
"type": "boolean"
},
"sql_parser_use_external_process": {
"title": "Sql Parser Use External Process",
"description": "When enabled, sql parser will run in isolated in a separate process. This can affect processing time but can protect from sql parser's mem leak.",
"default": false,
"type": "boolean"
},
"env": {
"title": "Env",
"description": "Environment to use in namespace when constructing URNs.",
"default": "PROD",
"type": "string"
},
"platform_instance": {
"title": "Platform Instance",
"description": "The instance of the platform that all assets produced by this recipe belong to",
"type": "string"
},
"stateful_ingestion": {
"title": "Stateful Ingestion",
"description": "DBT Stateful Ingestion Config.",
"allOf": [
{
"$ref": "#/definitions/StatefulStaleMetadataRemovalConfig"
}
]
},
"target_platform": {
"title": "Target Platform",
"description": "The platform that dbt is loading onto. (e.g. bigquery / redshift / postgres etc.)",
"type": "string"
},
"target_platform_instance": {
"title": "Target Platform Instance",
"description": "The platform instance for the platform that dbt is operating on. Use this if you have multiple instances of the same platform (e.g. redshift) and need to distinguish between them.",
"type": "string"
},
"use_identifiers": {
"title": "Use Identifiers",
"description": "Use model identifier instead of model name if defined (if not, default to model name).",
"default": false,
"type": "boolean"
},
"entities_enabled": {
"title": "Entities Enabled",
"description": "Controls for enabling / disabling metadata emission for different dbt entities (models, test definitions, test results, etc.)",
"default": {
"models": "YES",
"sources": "YES",
"seeds": "YES",
"snapshots": "YES",
"test_definitions": "YES",
"test_results": "YES"
},
"allOf": [
{
"$ref": "#/definitions/DBTEntitiesEnabled"
}
]
},
"tag_prefix": {
"title": "Tag Prefix",
"description": "Prefix added to tags during ingestion.",
"default": "dbt:",
"type": "string"
},
"node_name_pattern": {
"title": "Node Name Pattern",
"description": "regex patterns for dbt model names to filter in ingestion.",
"default": {
"allow": [
".*"
],
"deny": [],
"ignoreCase": true
},
"allOf": [
{
"$ref": "#/definitions/AllowDenyPattern"
}
]
},
"meta_mapping": {
"title": "Meta Mapping",
"description": "mapping rules that will be executed against dbt meta properties. Refer to the section below on dbt meta automated mappings.",
"default": {},
"type": "object"
},
"column_meta_mapping": {
"title": "Column Meta Mapping",
"description": "mapping rules that will be executed against dbt column meta properties. Refer to the section below on dbt meta automated mappings.",
"default": {},
"type": "object"
},
"query_tag_mapping": {
"title": "Query Tag Mapping",
"description": "mapping rules that will be executed against dbt query_tag meta properties. Refer to the section below on dbt meta automated mappings.",
"default": {},
"type": "object"
},
"write_semantics": {
"title": "Write Semantics",
"description": "Whether the new tags, terms and owners to be added will override the existing ones added only by this source or not. Value for this config can be \"PATCH\" or \"OVERRIDE\"",
"default": "PATCH",
"type": "string"
},
"strip_user_ids_from_email": {
"title": "Strip User Ids From Email",
"description": "Whether or not to strip email id while adding owners using dbt meta actions.",
"default": false,
"type": "boolean"
},
"enable_owner_extraction": {
"title": "Enable Owner Extraction",
"description": "When enabled, ownership info will be extracted from the dbt meta",
"default": true,
"type": "boolean"
},
"owner_extraction_pattern": {
"title": "Owner Extraction Pattern",
"description": "Regex string to extract owner from the dbt node using the `(?P<name>...) syntax` of the [match object](https://docs.python.org/3/library/re.html#match-objects), where the group name must be `owner`. Examples: (1)`r\"(?P<owner>(.*)): (\\w+) (\\w+)\"` will extract `jdoe` as the owner from `\"jdoe: John Doe\"` (2) `r\"@(?P<owner>(.*))\"` will extract `alice` as the owner from `\"@alice\"`.",
"type": "string"
},
"include_env_in_assertion_guid": {
"title": "Include Env In Assertion Guid",
"description": "Prior to version 0.9.4.2, the assertion GUIDs did not include the environment. If you're using multiple dbt ingestion that are only distinguished by env, then you should set this flag to True.",
"default": false,
"type": "boolean"
},
"convert_column_urns_to_lowercase": {
"title": "Convert Column Urns To Lowercase",
"description": "When enabled, converts column URNs to lowercase to ensure cross-platform compatibility. If `target_platform` is Snowflake, the default is True.",
"default": false,
"type": "boolean"
},
"use_compiled_code": {
"title": "Use Compiled Code",
"description": "When enabled, uses the compiled dbt code instead of the raw dbt node definition.",
"default": false,
"type": "boolean"
},
"test_warnings_are_errors": {
"title": "Test Warnings Are Errors",
"description": "When enabled, dbt test warnings will be treated as failures.",
"default": false,
"type": "boolean"
},
"enable_meta_mapping": {
"title": "Enable Meta Mapping",
"description": "When enabled, applies the mappings that are defined through the meta_mapping directives.",
"default": true,
"type": "boolean"
},
"enable_query_tag_mapping": {
"title": "Enable Query Tag Mapping",
"description": "When enabled, applies the mappings that are defined through the `query_tag_mapping` directives.",
"default": true,
"type": "boolean"
},
"manifest_path": {
"title": "Manifest Path",
"description": "Path to dbt manifest JSON. See https://docs.getdbt.com/reference/artifacts/manifest-json Note this can be a local file or a URI.",
"type": "string"
},
"catalog_path": {
"title": "Catalog Path",
"description": "Path to dbt catalog JSON. See https://docs.getdbt.com/reference/artifacts/catalog-json Note this can be a local file or a URI.",
"type": "string"
},
"sources_path": {
"title": "Sources Path",
"description": "Path to dbt sources JSON. See https://docs.getdbt.com/reference/artifacts/sources-json. If not specified, last-modified fields will not be populated. Note this can be a local file or a URI.",
"type": "string"
},
"test_results_path": {
"title": "Test Results Path",
"description": "Path to output of dbt test run as run_results file in JSON format. See https://docs.getdbt.com/reference/artifacts/run-results-json. If not specified, test execution results will not be populated in DataHub.",
"type": "string"
},
"aws_connection": {
"title": "Aws Connection",
"description": "When fetching manifest files from s3, configuration for aws connection details",
"allOf": [
{
"$ref": "#/definitions/AwsConnectionConfig"
}
]
},
"git_info": {
"title": "Git Info",
"description": "Reference to your git location to enable easy navigation from DataHub to your dbt files.",
"allOf": [
{
"$ref": "#/definitions/GitReference"
}
]
}
},
"required": [
"target_platform",
"manifest_path",
"catalog_path"
],
"additionalProperties": false,
"definitions": {
"DynamicTypedStateProviderConfig": {
"title": "DynamicTypedStateProviderConfig",
"type": "object",
"properties": {
"type": {
"title": "Type",
"description": "The type of the state provider to use. For DataHub use `datahub`",
"type": "string"
},
"config": {
"title": "Config",
"description": "The configuration required for initializing the state provider. Default: The datahub_api config if set at pipeline level. Otherwise, the default DatahubClientConfig. See the defaults (https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/src/datahub/ingestion/graph/client.py#L19)."
}
},
"required": [
"type"
],
"additionalProperties": false
},
"StatefulStaleMetadataRemovalConfig": {
"title": "StatefulStaleMetadataRemovalConfig",
"description": "Base specialized config for Stateful Ingestion with stale metadata removal capability.",
"type": "object",
"properties": {
"enabled": {
"title": "Enabled",
"description": "The type of the ingestion state provider registered with datahub.",
"default": false,
"type": "boolean"
},
"remove_stale_metadata": {
"title": "Remove Stale Metadata",
"description": "Soft-deletes the entities present in the last successful run but missing in the current run with stateful_ingestion enabled.",
"default": true,
"type": "boolean"
}
},
"additionalProperties": false
},
"EmitDirective": {
"title": "EmitDirective",
"description": "A holder for directives for emission for specific types of entities",
"enum": [
"YES",
"NO",
"ONLY"
]
},
"DBTEntitiesEnabled": {
"title": "DBTEntitiesEnabled",
"description": "Controls which dbt entities are going to be emitted by this source",
"type": "object",
"properties": {
"models": {
"description": "Emit metadata for dbt models when set to Yes or Only",
"default": "YES",
"allOf": [
{
"$ref": "#/definitions/EmitDirective"
}
]
},
"sources": {
"description": "Emit metadata for dbt sources when set to Yes or Only",
"default": "YES",
"allOf": [
{
"$ref": "#/definitions/EmitDirective"
}
]
},
"seeds": {
"description": "Emit metadata for dbt seeds when set to Yes or Only",
"default": "YES",
"allOf": [
{
"$ref": "#/definitions/EmitDirective"
}
]
},
"snapshots": {
"description": "Emit metadata for dbt snapshots when set to Yes or Only",
"default": "YES",
"allOf": [
{
"$ref": "#/definitions/EmitDirective"
}
]
},
"test_definitions": {
"description": "Emit metadata for test definitions when enabled when set to Yes or Only",
"default": "YES",
"allOf": [
{
"$ref": "#/definitions/EmitDirective"
}
]
},
"test_results": {
"description": "Emit metadata for test results when set to Yes or Only",
"default": "YES",
"allOf": [
{
"$ref": "#/definitions/EmitDirective"
}
]
}
},
"additionalProperties": false
},
"AllowDenyPattern": {
"title": "AllowDenyPattern",
"description": "A class to store allow deny regexes",
"type": "object",
"properties": {
"allow": {
"title": "Allow",
"description": "List of regex patterns to include in ingestion",
"default": [
".*"
],
"type": "array",
"items": {
"type": "string"
}
},
"deny": {
"title": "Deny",
"description": "List of regex patterns to exclude from ingestion.",
"default": [],
"type": "array",
"items": {
"type": "string"
}
},
"ignoreCase": {
"title": "Ignorecase",
"description": "Whether to ignore case sensitivity during pattern matching.",
"default": true,
"type": "boolean"
}
},
"additionalProperties": false
},
"AwsAssumeRoleConfig": {
"title": "AwsAssumeRoleConfig",
"type": "object",
"properties": {
"RoleArn": {
"title": "Rolearn",
"description": "ARN of the role to assume.",
"type": "string"
},
"ExternalId": {
"title": "Externalid",
"description": "External ID to use when assuming the role.",
"type": "string"
}
},
"required": [
"RoleArn"
]
},
"AwsConnectionConfig": {
"title": "AwsConnectionConfig",
"description": "Common AWS credentials config.\n\nCurrently used by:\n - Glue source\n - SageMaker source\n - dbt source",
"type": "object",
"properties": {
"aws_access_key_id": {
"title": "Aws Access Key Id",
"description": "AWS access key ID. Can be auto-detected, see [the AWS boto3 docs](https://boto3.amazonaws.com/v1/documentation/api/latest/guide/credentials.html) for details.",
"type": "string"
},
"aws_secret_access_key": {
"title": "Aws Secret Access Key",
"description": "AWS secret access key. Can be auto-detected, see [the AWS boto3 docs](https://boto3.amazonaws.com/v1/documentation/api/latest/guide/credentials.html) for details.",
"type": "string"
},
"aws_session_token": {
"title": "Aws Session Token",
"description": "AWS session token. Can be auto-detected, see [the AWS boto3 docs](https://boto3.amazonaws.com/v1/documentation/api/latest/guide/credentials.html) for details.",
"type": "string"
},
"aws_role": {
"title": "Aws Role",
"description": "AWS roles to assume. If using the string format, the role ARN can be specified directly. If using the object format, the role can be specified in the RoleArn field and additional available arguments are documented at https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sts.html?highlight=assume_role#STS.Client.assume_role",
"anyOf": [
{
"type": "string"
},
{
"type": "array",
"items": {
"anyOf": [
{
"type": "string"
},
{
"$ref": "#/definitions/AwsAssumeRoleConfig"
}
]
}
}
]
},
"aws_profile": {
"title": "Aws Profile",
"description": "Named AWS profile to use. Only used if access key / secret are unset. If not set the default will be used",
"type": "string"
},
"aws_region": {
"title": "Aws Region",
"description": "AWS region code.",
"type": "string"
},
"aws_endpoint_url": {
"title": "Aws Endpoint Url",
"description": "The AWS service endpoint. This is normally [constructed automatically](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/core/session.html), but can be overridden here.",
"type": "string"
},
"aws_proxy": {
"title": "Aws Proxy",
"description": "A set of proxy configs to use with AWS. See the [botocore.config](https://botocore.amazonaws.com/v1/documentation/api/latest/reference/config.html) docs for details.",
"type": "object",
"additionalProperties": {
"type": "string"
}
}
},
"required": [
"aws_region"
],
"additionalProperties": false
},
"GitReference": {
"title": "GitReference",
"description": "Reference to a hosted Git repository. Used to generate \"view source\" links.",
"type": "object",
"properties": {
"repo": {
"title": "Repo",
"description": "Name of your Git repo e.g. https://github.com/datahub-project/datahub or https://gitlab.com/gitlab-org/gitlab. If organization/repo is provided, we assume it is a GitHub repo.",
"type": "string"
},
"branch": {
"title": "Branch",
"description": "Branch on which your files live by default. Typically main or master. This can also be a commit hash.",
"default": "main",
"type": "string"
},
"url_template": {
"title": "Url Template",
"description": "Template for generating a URL to a file in the repo e.g. '{repo_url}/blob/{branch}/{file_path}'. We can infer this for GitHub and GitLab repos, and it is otherwise required.It supports the following variables: {repo_url}, {branch}, {file_path}",
"type": "string"
}
},
"required": [
"repo"
],
"additionalProperties": false
}
}
}
dbt meta automated mappings
dbt allows authors to define meta properties for datasets. Checkout this link to know more - dbt meta. Our dbt source allows users to define
actions such as add a tag, term or owner. For example if a dbt model has a meta config "has_pii": True, we can define an action
that evaluates if the property is set to true and add, lets say, a pii tag.
To leverage this feature we require users to define mappings as part of the recipe. The following section describes how you can build these mappings. Listed below is a meta_mapping and column_meta_mapping section that among other things, looks for keys like business_owner and adds owners that are listed there.
meta_mapping:
business_owner:
match: ".*"
operation: "add_owner"
config:
owner_type: user
owner_category: BUSINESS_OWNER
has_pii:
match: True
operation: "add_tag"
config:
tag: "has_pii_test"
int_property:
match: 1
operation: "add_tag"
config:
tag: "int_meta_property"
double_property:
match: 2.5
operation: "add_term"
config:
term: "double_meta_property"
data_governance.team_owner:
match: "Finance"
operation: "add_term"
config:
term: "Finance_test"
terms_list:
match: ".*"
operation: "add_terms"
config:
separator: ","
documentation_link:
match: "(?:https?)?\:\/\/\w*[^#]*"
operation: "add_doc_link"
config:
link: {{ $match }}
description: "Documentation Link"
column_meta_mapping:
terms_list:
match: ".*"
operation: "add_terms"
config:
separator: ","
is_sensitive:
match: True
operation: "add_tag"
config:
tag: "sensitive"
We support the following operations:
- add_tag - Requires
tagproperty in config. - add_term - Requires
termproperty in config. - add_terms - Accepts an optional
separatorproperty in config. - add_owner - Requires
owner_typeproperty in config which can be either user or group. Optionally accepts theowner_categoryconfig property which you can set to one of['TECHNICAL_OWNER', 'BUSINESS_OWNER', 'DATA_STEWARD', 'DATAOWNER'(defaults toDATAOWNER). - add_doc_link - Requires
linkanddescriptionproperties in config. Upon ingestion run, this will overwrite current links in the institutional knowledge section with this new link. The anchor text is defined here in the meta_mappings asdescription.
Note:
- The dbt
meta_mappingconfig works at the model level, while thecolumn_meta_mappingconfig works at the column level. Theadd_owneroperation is not supported at the column level. - For string meta properties we support regex matching.
With regex matching, you can also use the matched value to customize how you populate the tag, term or owner fields. Here are a few advanced examples:
Data Tier - Bronze, Silver, Gold
If your meta section looks like this:
meta:
data_tier: Bronze # chosen from [Bronze,Gold,Silver]
and you wanted to attach a glossary term like urn:li:glossaryTerm:Bronze for all the models that have this value in the meta section attached to them, the following meta_mapping section would achieve that outcome:
meta_mapping:
data_tier:
match: "Bronze|Silver|Gold"
operation: "add_term"
config:
term: "{{ $match }}"
to match any data_tier of Bronze, Silver or Gold and maps it to a glossary term with the same name.
Case Numbers - create tags
If your meta section looks like this:
meta:
case: PLT-4678 # internal Case Number
and you want to generate tags that look like case_4678 from this, you can use the following meta_mapping section:
meta_mapping:
case:
match: "PLT-(.*)"
operation: "add_tag"
config:
tag: "case_{{ $match }}"
Stripping out leading @ sign
You can also match specific groups within the value to extract subsets of the matched value. e.g. if you have a meta section that looks like this:
meta:
owner: "@finance-team"
business_owner: "@janet"
and you want to mark the finance-team as a group that owns the dataset (skipping the leading @ sign), while marking janet as an individual user (again, skipping the leading @ sign) that owns the dataset, you can use the following meta-mapping section.
meta_mapping:
owner:
match: "^@(.*)"
operation: "add_owner"
config:
owner_type: group
business_owner:
match: "^@(?P<owner>(.*))"
operation: "add_owner"
config:
owner_type: user
owner_category: BUSINESS_OWNER
In the examples above, we show two ways of writing the matching regexes. In the first one, ^@(.*) the first matching group (a.k.a. match.group(1)) is automatically inferred. In the second example, ^@(?P<owner>(.*)), we use a named matching group (called owner, since we are matching an owner) to capture the string we want to provide to the ownership urn.
dbt query_tag automated mappings
This works similarly as the dbt meta mapping but for the query tags
We support the below actions -
- add_tag - Requires
tagproperty in config.
The below example set as global tag the query tag tag key's value.
"query_tag_mapping":
{
"tag":
"match": ".*"
"operation": "add_tag"
"config":
"tag": "{{ $match }}"
}
Integrating with dbt test
To integrate with dbt tests, the dbt source needs access to the run_results.json file generated after a dbt test execution. Typically, this is written to the target directory. A common pattern you can follow is:
- Run
dbt docs generateand uploadmanifest.jsonandcatalog.jsonto a location accessible to thedbtsource (e.g. s3 or local file system) - Run
dbt testand uploadrun_results.jsonto a location accessible to thedbtsource (e.g. s3 or local file system) - Run
datahub ingest -c dbt_recipe.dhub.yamlwith the following config parameters specified- test_results_path: pointing to the run_results.json file that you just created
The connector will produce the following things:
- Assertion definitions that are attached to the dataset (or datasets)
- Results from running the tests attached to the timeline of the dataset
View of dbt tests for a dataset
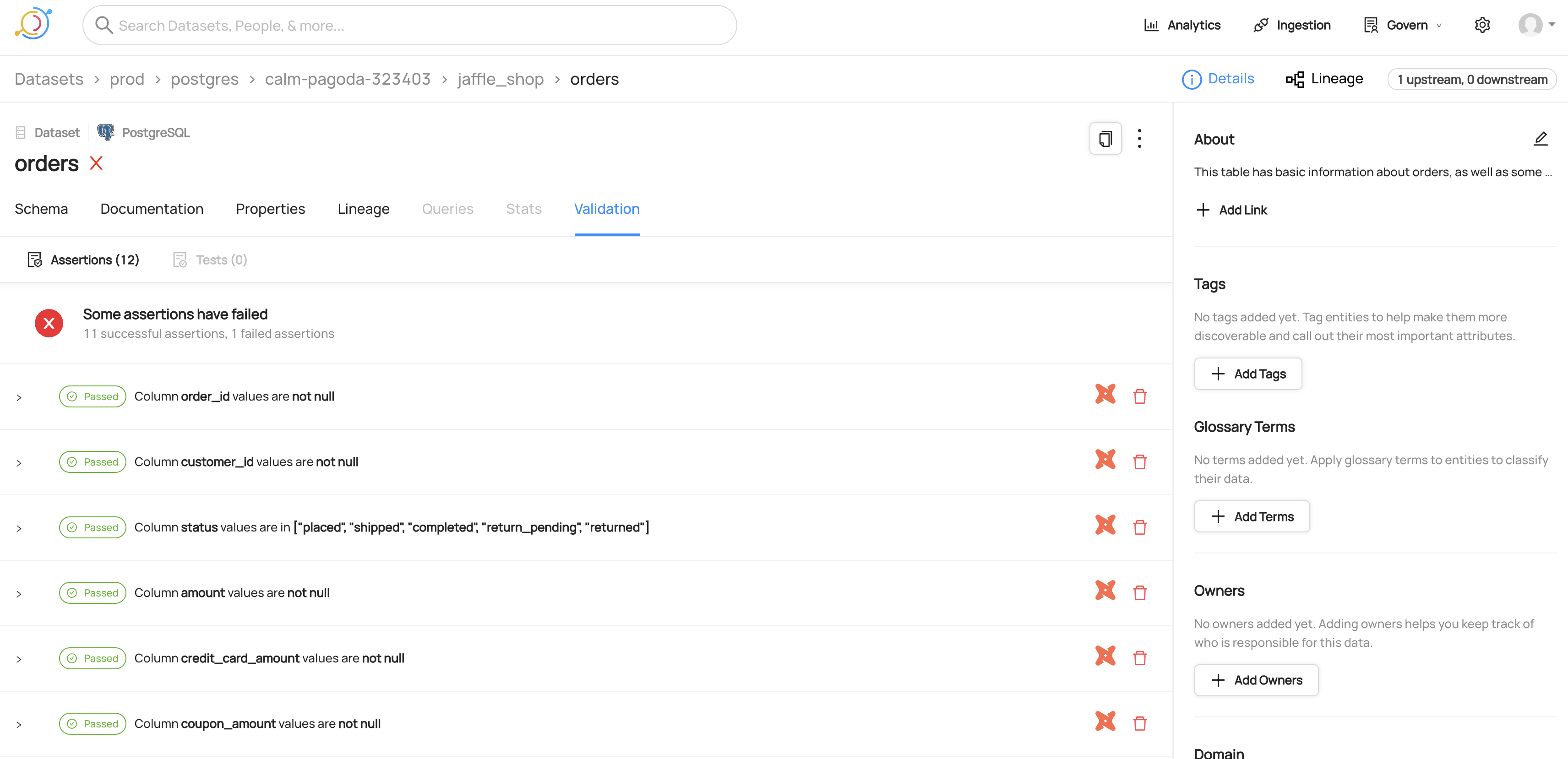
Viewing the SQL for a dbt test
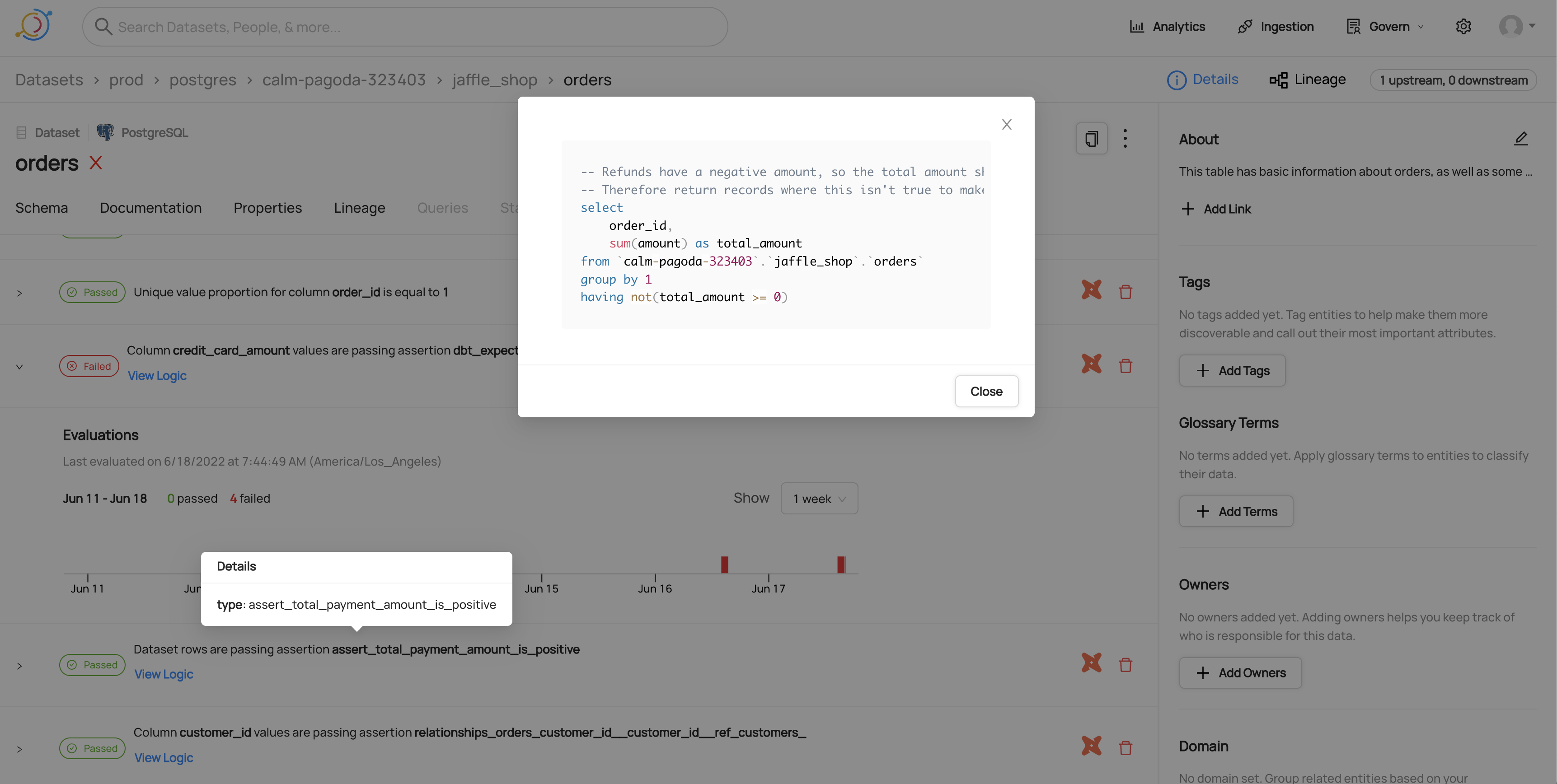
Viewing timeline for a failed dbt test
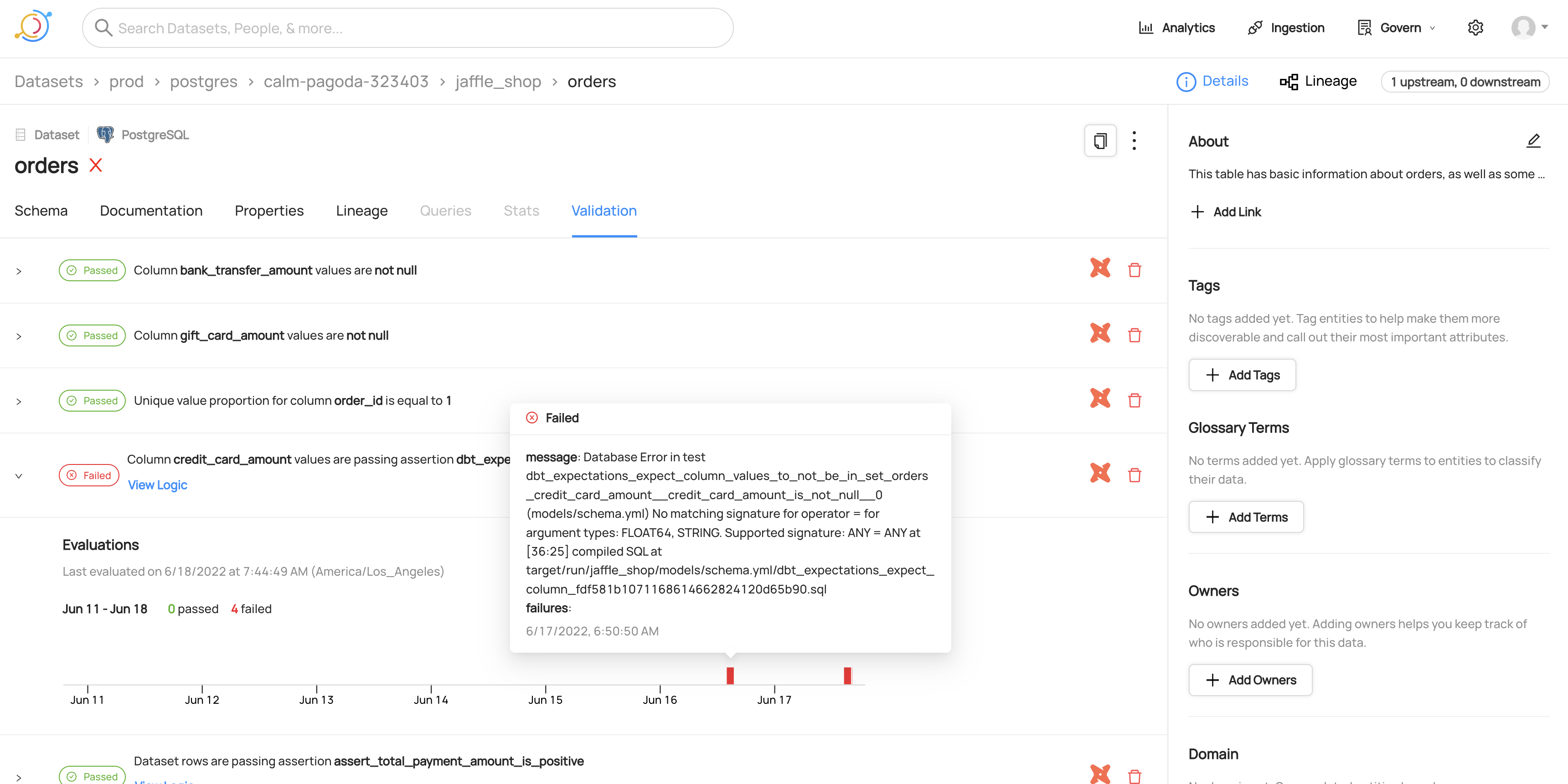
Separating test result emission from other metadata emission
You can segregate emission of test results from the emission of other dbt metadata using the entities_enabled config flag.
The following recipe shows you how to emit only test results.
source:
type: dbt
config:
manifest_path: _path_to_manifest_json
catalog_path: _path_to_catalog_json
test_results_path: _path_to_run_results_json
target_platform: postgres
entities_enabled:
test_results: Only
Similarly, the following recipe shows you how to emit everything (i.e. models, sources, seeds, test definitions) but not test results:
source:
type: dbt
config:
manifest_path: _path_to_manifest_json
catalog_path: _path_to_catalog_json
run_results_path: _path_to_run_results_json
target_platform: postgres
entities_enabled:
test_results: No
Code Coordinates
- Class Name:
datahub.ingestion.source.dbt.dbt_core.DBTCoreSource - Browse on GitHub
Module dbt-cloud
Important Capabilities
| Capability | Status | Notes |
|---|---|---|
| Dataset Usage | ❌ | |
| Detect Deleted Entities | ✅ | Enabled via stateful ingestion |
| Table-Level Lineage | ✅ | Enabled by default |
This source pulls dbt metadata directly from the dbt Cloud APIs.
You'll need to have a dbt Cloud job set up to run your dbt project, and "Generate docs on run" should be enabled.
The token should have the "read metadata" permission.
To get the required IDs, go to the job details page (this is the one with the "Run History" table), and look at the URL. It should look something like this: https://cloud.getdbt.com/next/deploy/107298/projects/175705/jobs/148094. In this example, the account ID is 107298, the project ID is 175705, and the job ID is 148094.
CLI based Ingestion
Install the Plugin
pip install 'acryl-datahub[dbt-cloud]'
Starter Recipe
Check out the following recipe to get started with ingestion! See below for full configuration options.
For general pointers on writing and running a recipe, see our main recipe guide.
source:
type: "dbt-cloud"
config:
token: ${DBT_CLOUD_TOKEN}
# In the URL https://cloud.getdbt.com/next/deploy/107298/projects/175705/jobs/148094,
# 107298 is the account_id, 175705 is the project_id, and 148094 is the job_id
account_id: "${DBT_ACCOUNT_ID}" # set to your dbt cloud account id
project_id: "${DBT_PROJECT_ID}" # set to your dbt cloud project id
job_id: "${DBT_JOB_ID}" # set to your dbt cloud job id
run_id: # set to your dbt cloud run id. This is optional, and defaults to the latest run
target_platform: postgres
# Options
target_platform: "${TARGET_PLATFORM_ID}" # e.g. bigquery/postgres/etc.
# sink configs
Config Details
- Options
- Schema
Note that a . is used to denote nested fields in the YAML recipe.
| Field | Description |
|---|---|
account_id ✅ integer | The DBT Cloud account ID to use. |
job_id ✅ integer | The ID of the job to ingest metadata from. |
project_id ✅ integer | The dbt Cloud project ID to use. |
target_platform ✅ string | The platform that dbt is loading onto. (e.g. bigquery / redshift / postgres etc.) |
token ✅ string | The API token to use to authenticate with DBT Cloud. |
column_meta_mapping object | mapping rules that will be executed against dbt column meta properties. Refer to the section below on dbt meta automated mappings. Default: {} |
convert_column_urns_to_lowercase boolean | When enabled, converts column URNs to lowercase to ensure cross-platform compatibility. If target_platform is Snowflake, the default is True. Default: False |
enable_meta_mapping boolean | When enabled, applies the mappings that are defined through the meta_mapping directives. Default: True |
enable_owner_extraction boolean | When enabled, ownership info will be extracted from the dbt meta Default: True |
enable_query_tag_mapping boolean | When enabled, applies the mappings that are defined through the query_tag_mapping directives. Default: True |
include_env_in_assertion_guid boolean | Prior to version 0.9.4.2, the assertion GUIDs did not include the environment. If you're using multiple dbt ingestion that are only distinguished by env, then you should set this flag to True. Default: False |
incremental_lineage boolean | When enabled, emits lineage as incremental to existing lineage already in DataHub. When disabled, re-states lineage on each run. Default: True |
meta_mapping object | mapping rules that will be executed against dbt meta properties. Refer to the section below on dbt meta automated mappings. Default: {} |
metadata_endpoint string | The dbt Cloud metadata API endpoint. |
owner_extraction_pattern string | Regex string to extract owner from the dbt node using the (?P<name>...) syntax of the match object, where the group name must be owner. Examples: (1)r"(?P<owner>(.*)): (\w+) (\w+)" will extract jdoe as the owner from "jdoe: John Doe" (2) r"@(?P<owner>(.*))" will extract alice as the owner from "@alice". |
platform_instance string | The instance of the platform that all assets produced by this recipe belong to |
query_tag_mapping object | mapping rules that will be executed against dbt query_tag meta properties. Refer to the section below on dbt meta automated mappings. Default: {} |
run_id integer | The ID of the run to ingest metadata from. If not specified, we'll default to the latest run. |
sql_parser_use_external_process boolean | When enabled, sql parser will run in isolated in a separate process. This can affect processing time but can protect from sql parser's mem leak. Default: False |
strip_user_ids_from_email boolean | Whether or not to strip email id while adding owners using dbt meta actions. Default: False |
tag_prefix string | Prefix added to tags during ingestion. Default: dbt: |
target_platform_instance string | The platform instance for the platform that dbt is operating on. Use this if you have multiple instances of the same platform (e.g. redshift) and need to distinguish between them. |
test_warnings_are_errors boolean | When enabled, dbt test warnings will be treated as failures. Default: False |
use_compiled_code boolean | When enabled, uses the compiled dbt code instead of the raw dbt node definition. Default: False |
use_identifiers boolean | Use model identifier instead of model name if defined (if not, default to model name). Default: False |
write_semantics string | Whether the new tags, terms and owners to be added will override the existing ones added only by this source or not. Value for this config can be "PATCH" or "OVERRIDE" Default: PATCH |
env string | Environment to use in namespace when constructing URNs. Default: PROD |
entities_enabled DBTEntitiesEnabled | Controls for enabling / disabling metadata emission for different dbt entities (models, test definitions, test results, etc.) Default: {'models': 'YES', 'sources': 'YES', 'seeds': 'YES'... |
entities_enabled.models Enum | Emit metadata for dbt models when set to Yes or Only Default: YES |
entities_enabled.seeds Enum | Emit metadata for dbt seeds when set to Yes or Only Default: YES |
entities_enabled.snapshots Enum | Emit metadata for dbt snapshots when set to Yes or Only Default: YES |
entities_enabled.sources Enum | Emit metadata for dbt sources when set to Yes or Only Default: YES |
entities_enabled.test_definitions Enum | Emit metadata for test definitions when enabled when set to Yes or Only Default: YES |
entities_enabled.test_results Enum | Emit metadata for test results when set to Yes or Only Default: YES |
node_name_pattern AllowDenyPattern | regex patterns for dbt model names to filter in ingestion. Default: {'allow': ['.*'], 'deny': [], 'ignoreCase': True} |
node_name_pattern.allow array(string) | |
node_name_pattern.deny array(string) | |
node_name_pattern.ignoreCase boolean | Whether to ignore case sensitivity during pattern matching. Default: True |
stateful_ingestion StatefulStaleMetadataRemovalConfig | DBT Stateful Ingestion Config. |
stateful_ingestion.enabled boolean | The type of the ingestion state provider registered with datahub. Default: False |
stateful_ingestion.remove_stale_metadata boolean | Soft-deletes the entities present in the last successful run but missing in the current run with stateful_ingestion enabled. Default: True |
The JSONSchema for this configuration is inlined below.
{
"title": "DBTCloudConfig",
"description": "Base configuration class for stateful ingestion for source configs to inherit from.",
"type": "object",
"properties": {
"incremental_lineage": {
"title": "Incremental Lineage",
"description": "When enabled, emits lineage as incremental to existing lineage already in DataHub. When disabled, re-states lineage on each run.",
"default": true,
"type": "boolean"
},
"sql_parser_use_external_process": {
"title": "Sql Parser Use External Process",
"description": "When enabled, sql parser will run in isolated in a separate process. This can affect processing time but can protect from sql parser's mem leak.",
"default": false,
"type": "boolean"
},
"env": {
"title": "Env",
"description": "Environment to use in namespace when constructing URNs.",
"default": "PROD",
"type": "string"
},
"platform_instance": {
"title": "Platform Instance",
"description": "The instance of the platform that all assets produced by this recipe belong to",
"type": "string"
},
"stateful_ingestion": {
"title": "Stateful Ingestion",
"description": "DBT Stateful Ingestion Config.",
"allOf": [
{
"$ref": "#/definitions/StatefulStaleMetadataRemovalConfig"
}
]
},
"target_platform": {
"title": "Target Platform",
"description": "The platform that dbt is loading onto. (e.g. bigquery / redshift / postgres etc.)",
"type": "string"
},
"target_platform_instance": {
"title": "Target Platform Instance",
"description": "The platform instance for the platform that dbt is operating on. Use this if you have multiple instances of the same platform (e.g. redshift) and need to distinguish between them.",
"type": "string"
},
"use_identifiers": {
"title": "Use Identifiers",
"description": "Use model identifier instead of model name if defined (if not, default to model name).",
"default": false,
"type": "boolean"
},
"entities_enabled": {
"title": "Entities Enabled",
"description": "Controls for enabling / disabling metadata emission for different dbt entities (models, test definitions, test results, etc.)",
"default": {
"models": "YES",
"sources": "YES",
"seeds": "YES",
"snapshots": "YES",
"test_definitions": "YES",
"test_results": "YES"
},
"allOf": [
{
"$ref": "#/definitions/DBTEntitiesEnabled"
}
]
},
"tag_prefix": {
"title": "Tag Prefix",
"description": "Prefix added to tags during ingestion.",
"default": "dbt:",
"type": "string"
},
"node_name_pattern": {
"title": "Node Name Pattern",
"description": "regex patterns for dbt model names to filter in ingestion.",
"default": {
"allow": [
".*"
],
"deny": [],
"ignoreCase": true
},
"allOf": [
{
"$ref": "#/definitions/AllowDenyPattern"
}
]
},
"meta_mapping": {
"title": "Meta Mapping",
"description": "mapping rules that will be executed against dbt meta properties. Refer to the section below on dbt meta automated mappings.",
"default": {},
"type": "object"
},
"column_meta_mapping": {
"title": "Column Meta Mapping",
"description": "mapping rules that will be executed against dbt column meta properties. Refer to the section below on dbt meta automated mappings.",
"default": {},
"type": "object"
},
"query_tag_mapping": {
"title": "Query Tag Mapping",
"description": "mapping rules that will be executed against dbt query_tag meta properties. Refer to the section below on dbt meta automated mappings.",
"default": {},
"type": "object"
},
"write_semantics": {
"title": "Write Semantics",
"description": "Whether the new tags, terms and owners to be added will override the existing ones added only by this source or not. Value for this config can be \"PATCH\" or \"OVERRIDE\"",
"default": "PATCH",
"type": "string"
},
"strip_user_ids_from_email": {
"title": "Strip User Ids From Email",
"description": "Whether or not to strip email id while adding owners using dbt meta actions.",
"default": false,
"type": "boolean"
},
"enable_owner_extraction": {
"title": "Enable Owner Extraction",
"description": "When enabled, ownership info will be extracted from the dbt meta",
"default": true,
"type": "boolean"
},
"owner_extraction_pattern": {
"title": "Owner Extraction Pattern",
"description": "Regex string to extract owner from the dbt node using the `(?P<name>...) syntax` of the [match object](https://docs.python.org/3/library/re.html#match-objects), where the group name must be `owner`. Examples: (1)`r\"(?P<owner>(.*)): (\\w+) (\\w+)\"` will extract `jdoe` as the owner from `\"jdoe: John Doe\"` (2) `r\"@(?P<owner>(.*))\"` will extract `alice` as the owner from `\"@alice\"`.",
"type": "string"
},
"include_env_in_assertion_guid": {
"title": "Include Env In Assertion Guid",
"description": "Prior to version 0.9.4.2, the assertion GUIDs did not include the environment. If you're using multiple dbt ingestion that are only distinguished by env, then you should set this flag to True.",
"default": false,
"type": "boolean"
},
"convert_column_urns_to_lowercase": {
"title": "Convert Column Urns To Lowercase",
"description": "When enabled, converts column URNs to lowercase to ensure cross-platform compatibility. If `target_platform` is Snowflake, the default is True.",
"default": false,
"type": "boolean"
},
"use_compiled_code": {
"title": "Use Compiled Code",
"description": "When enabled, uses the compiled dbt code instead of the raw dbt node definition.",
"default": false,
"type": "boolean"
},
"test_warnings_are_errors": {
"title": "Test Warnings Are Errors",
"description": "When enabled, dbt test warnings will be treated as failures.",
"default": false,
"type": "boolean"
},
"enable_meta_mapping": {
"title": "Enable Meta Mapping",
"description": "When enabled, applies the mappings that are defined through the meta_mapping directives.",
"default": true,
"type": "boolean"
},
"enable_query_tag_mapping": {
"title": "Enable Query Tag Mapping",
"description": "When enabled, applies the mappings that are defined through the `query_tag_mapping` directives.",
"default": true,
"type": "boolean"
},
"metadata_endpoint": {
"title": "Metadata Endpoint",
"description": "The dbt Cloud metadata API endpoint.",
"default": "https://metadata.cloud.getdbt.com/graphql",
"type": "string"
},
"token": {
"title": "Token",
"description": "The API token to use to authenticate with DBT Cloud.",
"type": "string"
},
"account_id": {
"title": "Account Id",
"description": "The DBT Cloud account ID to use.",
"type": "integer"
},
"project_id": {
"title": "Project Id",
"description": "The dbt Cloud project ID to use.",
"type": "integer"
},
"job_id": {
"title": "Job Id",
"description": "The ID of the job to ingest metadata from.",
"type": "integer"
},
"run_id": {
"title": "Run Id",
"description": "The ID of the run to ingest metadata from. If not specified, we'll default to the latest run.",
"type": "integer"
}
},
"required": [
"target_platform",
"token",
"account_id",
"project_id",
"job_id"
],
"additionalProperties": false,
"definitions": {
"DynamicTypedStateProviderConfig": {
"title": "DynamicTypedStateProviderConfig",
"type": "object",
"properties": {
"type": {
"title": "Type",
"description": "The type of the state provider to use. For DataHub use `datahub`",
"type": "string"
},
"config": {
"title": "Config",
"description": "The configuration required for initializing the state provider. Default: The datahub_api config if set at pipeline level. Otherwise, the default DatahubClientConfig. See the defaults (https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/src/datahub/ingestion/graph/client.py#L19)."
}
},
"required": [
"type"
],
"additionalProperties": false
},
"StatefulStaleMetadataRemovalConfig": {
"title": "StatefulStaleMetadataRemovalConfig",
"description": "Base specialized config for Stateful Ingestion with stale metadata removal capability.",
"type": "object",
"properties": {
"enabled": {
"title": "Enabled",
"description": "The type of the ingestion state provider registered with datahub.",
"default": false,
"type": "boolean"
},
"remove_stale_metadata": {
"title": "Remove Stale Metadata",
"description": "Soft-deletes the entities present in the last successful run but missing in the current run with stateful_ingestion enabled.",
"default": true,
"type": "boolean"
}
},
"additionalProperties": false
},
"EmitDirective": {
"title": "EmitDirective",
"description": "A holder for directives for emission for specific types of entities",
"enum": [
"YES",
"NO",
"ONLY"
]
},
"DBTEntitiesEnabled": {
"title": "DBTEntitiesEnabled",
"description": "Controls which dbt entities are going to be emitted by this source",
"type": "object",
"properties": {
"models": {
"description": "Emit metadata for dbt models when set to Yes or Only",
"default": "YES",
"allOf": [
{
"$ref": "#/definitions/EmitDirective"
}
]
},
"sources": {
"description": "Emit metadata for dbt sources when set to Yes or Only",
"default": "YES",
"allOf": [
{
"$ref": "#/definitions/EmitDirective"
}
]
},
"seeds": {
"description": "Emit metadata for dbt seeds when set to Yes or Only",
"default": "YES",
"allOf": [
{
"$ref": "#/definitions/EmitDirective"
}
]
},
"snapshots": {
"description": "Emit metadata for dbt snapshots when set to Yes or Only",
"default": "YES",
"allOf": [
{
"$ref": "#/definitions/EmitDirective"
}
]
},
"test_definitions": {
"description": "Emit metadata for test definitions when enabled when set to Yes or Only",
"default": "YES",
"allOf": [
{
"$ref": "#/definitions/EmitDirective"
}
]
},
"test_results": {
"description": "Emit metadata for test results when set to Yes or Only",
"default": "YES",
"allOf": [
{
"$ref": "#/definitions/EmitDirective"
}
]
}
},
"additionalProperties": false
},
"AllowDenyPattern": {
"title": "AllowDenyPattern",
"description": "A class to store allow deny regexes",
"type": "object",
"properties": {
"allow": {
"title": "Allow",
"description": "List of regex patterns to include in ingestion",
"default": [
".*"
],
"type": "array",
"items": {
"type": "string"
}
},
"deny": {
"title": "Deny",
"description": "List of regex patterns to exclude from ingestion.",
"default": [],
"type": "array",
"items": {
"type": "string"
}
},
"ignoreCase": {
"title": "Ignorecase",
"description": "Whether to ignore case sensitivity during pattern matching.",
"default": true,
"type": "boolean"
}
},
"additionalProperties": false
}
}
}
Code Coordinates
- Class Name:
datahub.ingestion.source.dbt.dbt_cloud.DBTCloudSource - Browse on GitHub
Questions
If you've got any questions on configuring ingestion for dbt, feel free to ping us on our Slack.